Overview
안녕하세요~! 얼떨결에 별별 DBA의 두번째 이야기가 되었네요.
MySQL 8.0이 처음 시장에 오픈된 시기는 2016-09-12 (Development Milestone)이고 정식 GA 버전으로 출시된게 2018-04-19 이니 어느 덧 2년의 시간이 넘었지만 생각보다 주변에서 8.0에 대한 레퍼런스를 듣는게 흔치는 않은 것 같습니다.
오늘 포스팅하는 내용은 MySQL 8.0 업그레이드를 검토하고 계신 분들에게 약간의 도움? 혹은 서로 정보 교류를 할 수 있는 시간이 되었으면 좋겠다는 취지에서 지난 1년 간 실무에서 경험한 8.0 업그레이드를 진행하며 겪은 이슈 상황들을 가볍게 공유하려 합니다.
Why MySQL 8.0? Instance Alter!
여전히 저는 서비스 민감도가 매우 높은 서비스라면 8.0을 도입하는 부분에서 아직 망설여지는 것이 사실이지만…. 그럼에도 불구하고 DBA 관점에서 8.0의 놓칠 수 없는 매력적인 기능을 뽑자면?
저는 개선된 Instance Alter를 뽑아보고 싶습니다. (테이블 사이즈에 구애 없이 alter 커맨드 날리는 순간 바로 적용 뽝! @_@) 만약 Table 사이즈가 500GB ~ XTB 단위이며, 스키마 변경이 잦은 서비스를 운영하고 있는 DBA라면 간단한 스키마 변경일지라도 작업 때 마다 고통 받을 것입니다.
더군다나 Percona pt-online-schema-change 을 사용하더라도..작업이 끝나갈 무렵, 서비스적인 Long query 혹은 트랜잭션 누수(SELECT구문이 포함된 트랜잭션이 정상적으로 종료-commit/rollback 되지 않은 상황)로 인한 Meta data lock을 맞딱뜨리며, 8시간 이상 수행된 alter 작업이 취소될 때에는.. MySQL8.0이 더욱 절실하게 생각나는 새벽이 되고 맙니다.
사실 저 Lock Wait로 인해 테이블을 마지막에 swap 하지 못하고 취소된 케이스에 대해서는 pt-online-schema-change 작업을 수동으로 완료시키는 방향으로 그린님과 논의를 통하여 검증은 했지만, 실 서버에서 쓰기에는 아직 꺼림칙해서 시도는 못해봤네요.
pt-online-schema-change의 자세한 동작은 그린님의 블로그를 읽어 보면 도움이 되겠네요.
— 참고 링크 (pt-online-schema-change 진행 과정 Green)
https://greendo.net/2019/12/22/pt-osc-general-log
다시 본론으로 돌아와서, 개인적인 의견으로는
"서비스 민감도가 크지 않다 & 데이터 사이즈가 크다 & 스키마 변경이 잦은" 환경에서는 MySQL 8.0 도입을 적극적으로 검토해 보는 것도 좋을 듯 합니다.^^
- 8.0 Instant Alter 참고
https://dev.mysql.com/doc/refman/8.0/en/innodb-online-ddl-operations.html
Add 컬럼의 경우 after 구문 없이 가장 마지막 컬럼으로 추가해야 하는 제약이 있으며, varchar type의 modify 시 기존 255 bytes가 증가 혹은 감소시 Instant Alter로는 동작하지 못하는 제약이 기존 5.7과 동일합니다.
실질적으로 Add 컬럼과 Index Rename 시 유용한 것 같습니다. ^^
Pre-checklists
이제 MySQL 8.0 업그레이드를 준비하는 과정 중 발생 할 수 있는 이슈들에 대해서 말씀 드리겠습니다. (제가 경험한 따끈한 이야기입니다.)
1. Connector/j 버전 체크
자바를 사용하는 환경에서는 Connector 버전(5.1.46 이상 혹은 8 버전) 체크를 하셔야합니다.
아무래도 DB 업그레이드 작업이니 가장 중요한 일정을 산정할 때, DBA의 기준에서 일정을 산정하게 될텐데요. DB 업그레이드 작업의 필수 선행 조건 중 하나는 개발자분들이 먼저 현재의 개발 환경을 바꿔주셔야 합니다. 만약 이 부분에 대한 위험성을 사전에 충분히 개발팀에 공지하지 않은 상태로 업그레이드를 진행했다가 장애가 발생하게 되면 서로 난감한 상황이 됩니다.. (구 버전 JDBC Connector는 MySQL 8.0에 접근 조차 하지 못하게 됩니다.)
그러므로 개발자분들이 먼저 DB에 접근하는 모든 웹/앱 서버의 JDBC Connector 버전을 체크 및 사전 변경을 해주는 부분이 8.0 업그레이드를 준비하는 과정에서 가장 첫 번째 작업입니다.
Changes in MySQL Connector/J 5.1.45 (2017-11-30)
Version 5.1.45 is a maintenance release of the production 5.1 branch. It is suitable for use with MySQL Server versions 5.5, 5.6, and 5.7. It supports the Java Database Connectivity (JDBC) 4.2 API.Changes in MySQL Connector/J 5.1.46 (2018-03-12)
Version 5.1.46 is a maintenance release of the production 5.1 branch. It is suitable for use with MySQL Server versions 5.5, 5.6, 5.7, and 8.0. It supports the Java Database Connectivity (JDBC) 4.2 API.
참고 : https://dev.mysql.com/doc/relnotes/connector-j/5.1/en/news-5-1.html
2. 롤백을 대비한 5.7 호환 콜레이션 지정
하늘이 무너져도 롤백은 가능하자!
DB 작업의 경우 그 민감도가 워낙 크다 보니 비단 업그레이드 작업 뿐 아니라 DB와 관련된 모든 일련의 작업 계획 중 롤백은 필수 불가결입니다. 그러나 준비하는 과정 중 생각보다 8.0 업그레이드에 대한 정보가 그리 많지는 않았습니다.
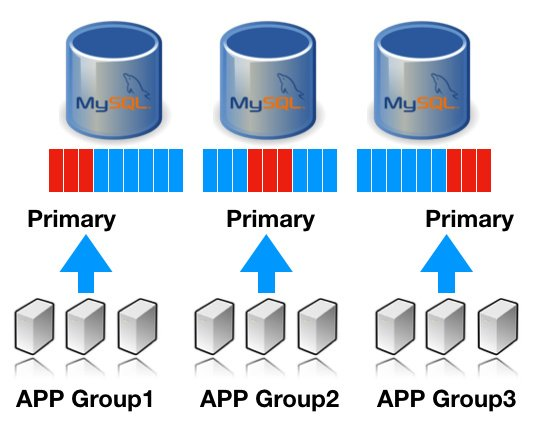
DB 서버 교체 or Upgrade를 준비하는 일반적인 아키텍처 구조는 대부분 비슷할 것 같은데요.
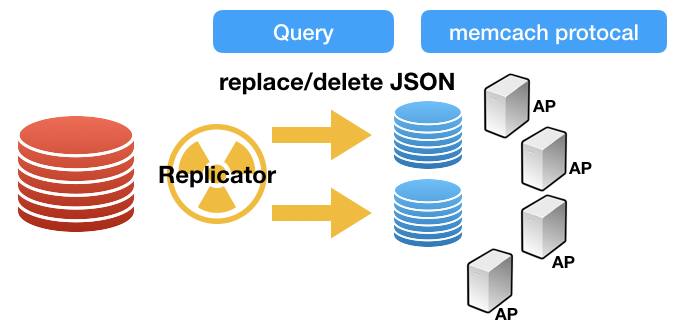
여기서 포인트는 빨간색 리플리케이션 연결선입니다.
5.7 -> 8.0 업그레이드를 위한 데이터 동기화가 역시 필수이며, 8.0 으로 서비스 전환된 이후에 롤백을 위해서도 변경된 데이터들이 5.7로 동기화 되어야 합니다.
그러나 이미 MySQL 8.0 -> 5.7 Replicate 연결을 구성할 경우, 아래와 같은 에러를 만나는 케이스를 접해 보셨을 거라 봅니다.
-- 8.0 마스터 cnf 설정
character_set_server= utf8mb4
collation_server = utf8mb4_general_ci
-- DDL 수행
mysql_8.0> create database 80_test;
Query OK, 1 row affected (0.00 sec)
mysql_8.0> show create database 80_test;
+----------+-----------------------------------------------------------------------------------------------------------------------------------+
| Database | Create Database |
+----------+-----------------------------------------------------------------------------------------------------------------------------------+
| 80_test | CREATE DATABASE `80_test` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ |
+----------+-----------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
-- 5.7 슬레이브 cnf 설정
character_set_server= utf8mb4
collation_server = utf8mb4_general_ci
-- Replicate 동기화 상태
ysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: test-8_0
Master_User: sun
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000069
Read_Master_Log_Pos: 594
Relay_Log_File: relay-bin.000004
Relay_Log_Pos: 567
Relay_Master_Log_File: binlog.000069
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 22
Last_Error: Error 'Character set '#255' is not a compiled character set and is not specified in the '/home/db/mysql/share/charsets/Index.xml' file' on query. Default database: '80_test'. Query: 'create database 80_test'이는 MySQL 8.0부터 새로 도입된 0900 콜레이션의 정보가 바이너리 로그에 함께 저장되면서 하위 버전들은 이를 인식하지 못하여 Replication Error를 발생하게 됩니다.
문제는 8.0의 케릭터셋 + 콜레이션 설정을 하위 5 버전과 동일하게 맞춰도 mysql 클라이언트로 접근 하여 DB 변경 작업을 진행 할 경우 해당 에러가 발생할 수 있습니다.
jdbc의 경우에는 connectionCollation 파라메터를 통해 케릭터 셋 제어가 가능하므로 실제 서비스에서 사용되는 쿼리는 문제가 없었습니다.
참고로, 8.0 바이너리 로그 저장된 형태로, 255번 collation이 추가된 것을 확인할 수 있습니다. 255번 콜레이션 경우 MySQL5 버전에는 존재하지 않기 때문에, 동기화 과정 중 에러가 발생됩니다.
SET @@session.character_set_client=255,@@session.collation_connection=255,@@session.collation_server=45/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;해당 케이스를 회피하고 8.0의 저장되는 바이너리 로그를 기존과 같이 저장시키기 위해서 my.cnf의 파라메터들을 아래와 같이 변경해 준 후, 하위 버전과 연결이 가능하게 되었습니다. init_connect을 통해, 모든 클라이언트 연결 시 강제로 캐릭터셋과 콜레이션을 호환하도록 강제하였습니다.
캐릭터셋 호환용 cnf 설정
--my.cnf
character_set_server= utf8mb4
collation-server = utf8mb4_general_ci
init_connect='SET NAMES utf8mb4 COLLATE utf8mb4_general_ci'
skip_character_set_client_handshake위와 같이 init_connect 파라메터 적용한 이후 바이너리로그를 확인해보면 아래와 같이 정상적으로 45번 콜레이션으로 기록되어있음을 확인해볼 수 있습니다.
SET @@session.character_set_client=45,@@session.collation_connection=45,@@session.collation_server=45/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;3. optimizer_switch 핸들링
optimizer_switch는 매 버전 업그레이드를 진행하게 될 때 마다 DBA가 가장 신경 써서 봐야 하는 주요 파라메터 중 하나이며, 이번 8.0의 경우에도 다양한 기능들이 추가 되었는데요. 그 중 특히 Oracle DB에서도 볼 수 있는 기능인 hash_join / skip_scan 의 경우는 설정에 더 많은 주의가 필요할 것 같습니다.
해당 파라메터가 ON 되어 있는 상태라면 기존에 잘 돌아가던 쿼리들이 문제가
없는지 사전에 철저하게 검수를 통해서 확인해야 하며, 가급적 운영 중 발생할 수 있는 돌발 상황을 고려한다면 저는 개인적으로 해당 파라메터들은 아직까지 OFF로 두는 것을 조심스럽게 추천합니다.
skip_scan 이슈로 기존 서비스 쿼리의 성능이 최대 10배 이상 떨어진 케이스
-- 스키마
CREATE TABLE `test_table` (
`domain_id` bigint NOT NULL COMMENT 'domain_id',
`domain_type` char(1) COLLATE utf8mb4_bin NOT NULL,
-- 컬럼명 생략,
PRIMARY KEY (`domain_id`,`svc_code`,`uid`,`uid_type`),
KEY `test_table_idx01` (`svc_code`,`used_rate`),
KEY `test_table_idx02` (`domain_id`,`uid_type`,`svc_code`),
KEY `test_table_idx03` (`domain_id`,`uid_type`,`uid`),
KEY `test_table_idx04` (`domain_type`,`domain_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
-- 선행 PK 조회 조건
mysql> select count(1) FROM test_table WHERE domain_id = 100 ;
+----------+
| count(1) |
+----------+
| 282532 |
+----------+
1 row in set (0.09 sec)
-- 선행 PK 컬럼인 domain_id의 이퀄 조건임에도 Using index for skip scan으로 (`domain_type`,`domain_id`) 엉뚱한 인덱스를 선택하여 스킵 스캔 수행
mysql> explain select count(1) FROM test_table WHERE domain_id = 100
+----+-------------+------------------------------+------------+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------+---------+------+------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------------------------+------------+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------+---------+------+------+----------+----------------------------------------+
| 1 | SIMPLE | test_table | NULL | range | PRIMARY,test_table_idx01,test_table_idx02,test_table_idx03,test_table_idx04,test_table_idx05 | test_table_idx04 | 12 | NULL | 2369 | 50.00 | Using where; Using index for skip scan |
+----+-------------+------------------------------+------------+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------+---------+------+------+----------+----------------------------------------+
1 row in set, 1 warning (0.00 sec)
-- 힌트를 통해 플랜은 변경 가능
explain select count(1) FROM test_table use index(PRIMARY) WHERE domain_id = 100
+----+-------------+------------------------------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------------------------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | test_table | NULL | range | PRIMARY | PRIMARY | 266 | NULL | 545989 | 100.00 | Using where; Using index |
+----+-------------+------------------------------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
-- 통계 정보 최대 수치로 갱신해도 skip되는 플랜은 변하지 않음
mysql> set global innodb_stats_persistent_sample_pages=100;
Query OK, 0 rows affected (0.00 sec)
mysql> ANALYZE TABLE test_table;
+------------------------------------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+------------------------------------------+---------+----------+----------+
| cloudcommon.test_table | analyze | status | OK |
+------------------------------------------+---------+----------+----------+
1 row in set (0.09 sec)
mysql> explain select count(*) FROM test_table WHERE domain_id = 100 ;
+----+-------------+------------------------------+------------+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------+---------+------+------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------------------------+------------+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------+---------+------+------+----------+----------------------------------------+
| 1 | SIMPLE | test_table | NULL | range | PRIMARY,test_table_idx01,test_table_idx02,test_table_idx03,test_table_idx04,test_table_idx05 | test_table_idx04 | 12 | NULL | 2397 | 100.00 | Using where; Using index for skip scan |
+----+-------------+------------------------------+------------+-------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------+---------+------+------+----------+----------------------------------------+
1 row in set, 1 warning (0.00 sec)
- 실제 수행되는 쿼리의 경우 이보다 복잡하여 반응속도는 더욱 더 현저하게 떨어짐4. 예약어 이슈 (함정 버전 주의)
작년에 한창 8.0 업그레이드를 진행하던 중 의외의 복병인 Reserved Word인 member를 만나서 작업을 홀딩하게 되었는데요.
mysql_8.0.17> show create table member;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'member' at line 1서비스에서 가장 보편적으로 사용되는 단어인 member가 갑작스레 8.0 예약어로 투입되었다가 제거되었습니다. -_-;;
added in 8.0.17 (reserved); became nonreserved in 8.0.19
어찌보면 17~18 단 두개의 릴리즈를 끝으로 급하게 제거된 사유는 많은 고객들의 항의가 있었을 것으로 추측되네요..^^;
그 외 8.0에서 추가된 예약어들이 현재 서비스와 충돌되는 부분이 없는지는 사전에 체크해야겠지요?
— 8.0 Reserved Words
https://dev.mysql.com/doc/refman/8.0/en/keywords.html
5. 그 외 체크 사항
5.1. Query Cache는 드디어 제거
Query Cache가 굉장히 효율적으로 동작하는 환경 자체가 흔하지는 않았던 것 같아서 저는 Oracle 사의 이번 과감한 Remove 정책을 환영합니다. 데이터 변경이 잦은 환경 + 자동 Fail-Over 환경에서는 오히려 잘못된 Query Cache 설정이 독이 되는 케이스가 참으로 많았습니다.
만약 Query Cache를 효율적으로 잘 사용하고 있었던 환경이라면 업그레이드 전 이에 대한 사전 체크도 충분히 해야 할 것 으로 보입니다.
(예를들면, MySQL을 백엔드로 PowerDNS를 구성한 경우와 같은..)
5.2 JDBC Connector 버전의 DB 접근 이슈
이는 비단 MySQL 8.0 뿐 아니라 5 버전에서 동일한 이슈입니다.
그러나 JDBC Connector 버전이 8.0 DB에 맞춰 올라감에 따라 발생 할 수 있는 이슈 입니다.
관련 에러 내역 : The server time zone value ‘KST’ is unrecognized or represents more than one time zone.
해결 방안은 KST 기준 JDBC or my.cnf의 설정 중 하나를 변경해주면 됩니다.
- jdbc 설정 : serverTimezone=Asia/Seoul
- my.cnf 설정 : default_time_zone = ‘+09:00’
5.3. 테이블 대/소문자 구분(lower_case_table_names) 운영중 변경 불가
어플리케이션에서 테이블 호출 시 대소문자를 정확하게 구분해서 사용하는 것이 베스트이지만!
- 우리는 솔루션이라 소스 수정이 안되요..
- 이미 구분 안하는 코드들로 너무 먼길을 걸어왔어요..
등의 사유로 테이블의 대소문자를 구분 안하고 호출 되는 혼돈의 환경이라면
lower_case_table_names= 0 -> 1 으로 초기 설치할 때 부터 맞춰 줘야 합니다. 기존 MySQL 5 버전들은 운영 중이라도 Offline으로 파라메터 변경이 가능했지만 MySQL 8.0 부터는 초기 설치 진행 시에만 변경이 가능하므로 이 부분 꼭 주의 하셔야 합니다!
— lower_case_table_names decument link
https://dev.mysql.com/doc/refman/8.0/en/server-system-variables.html#sysvar_lower_case_table_names
5.4. expire_logs_days 파라메터 변경
쌓여가는 바이너리 로그를 일 단위의 주기로 삭제하던 파라메터인 expire_logs_days가 드디어 초단위로 삭제할 수 있게 변경되었습니다.
expire_logs_days > binlog_expire_logs_seconds
디폴트 값은 2592000 (30일)
하루에도 엄청나게 쌓여가는 바이너리 로그로 문제가 되는 서비스 환경에서는
일 단위 삭제가 사실 무의미한 옵션이라서 별도의 삭제 배치를 만들어 관리했는데요. 이제는 초 단위로 삭제 주기를 조정 가능하므로 이용하기 수월해 진 것 같습니다.
바이너리 로그는 복구에 필수적인 로그 파일이므로, 삭제를 진행 전 해당 로그의 리모트 백업 유무 or 복구 정책에 대한 저마다 명확한 기준이 있을거라고 봅니다.
5.5. 0900_ai_ci collation의 이슈
MySQL 8.0의 디폴트 콜레이션은 0900_ai_ci 이며,
0900 콜레이션의 변경으로 기존 콜레이션 대비 성능이 더욱 더 향상 되었다고 합니다.
그러나 0900_ai_ci는 특문/외래어에 대한 인식 처리가 기존 5.7 general_ci 디폴트 방식과는 다릅니다. 특히 일본어 가타카나/히라가나를 같은 문자열로 인식하여 처리 하기 때문에 글로벌 서비스인 경우 콜레이션 설정을 반드시 주의 해야 합니다.
-- 콜레이션 utf8mb4_general_ci
mysql> select member_usid, member_name, hex(member_name) from member where member_name like '%ss%';
+-----------------+-------------+------------------+
| member_usid | member_name | hex(member_name) |
+-----------------+-------------+------------------+
| xxxxxxxxxxxxxxxx1 | ss | EFBD93EFBD93 |
+-----------------+-------------+------------------+
1 row in set (0.00 sec)
-- 콜레이션 utf8mb4_0900_ai_ci
mysql> select member_usid,member_name, hex(member_name) from `member` where member_name = 'ss';
+-----------------+-------------+------------------+
| member_usid | member_name | hex(member_name) |
+-----------------+-------------+------------------+
| xxxxxxxxxxxxxxxx2 | SS | 5353 |
| xxxxxxxxxxxxxxxx1 | ss | EFBD93EFBD93 |
+-----------------+-------------+------------------+
2 rows in set (0.00 sec)
-- 콜레이션 utf8mb4_general_ci
mysql> select member_usid, member_name, hex(member_name) from `member` where member_name='タナカ';
+-----------------+-------------+--------------------+
| member_usid | member_name | hex(member_name) |
+-----------------+-------------+--------------------+
| xxxxxxxxxxxxxxxx1 | タナカ | E382BFE3838AE382AB |
+-----------------+-------------+--------------------+
1 row in set (0.00 sec)
-- 콜레이션 utf8mb4_0900_ai_ci
mysql> select member_usid, member_name, hex(member_name) from `member` where member_name='タナカ';
+-----------------+-------------+--------------------+
| member_id | member_name | hex(member_name) |
+-----------------+-------------+--------------------+
| xxxxxxxxxxxxxxxx2 | たなか | E3819FE381AAE3818B |
| xxxxxxxxxxxxxxxx1 | タナカ | E382BFE3838AE382AB |
+-----------------+-------------+--------------------+
2 rows in set (0.00 sec)0900_as_cs를 사용하게 되면 위 이슈들을 해결할 수는 있지만..
기존 서비스 데이터를 그대로 가져와서 사용해야 하는 업그레이드 작업 관점에서 본다면 콜레이션은 가급적 기존과 동일하게 맞춰주는 것이 리스크가 없을 것으로 보입니다.
5.6 mysqldump 디폴트 옵션 변경 사항
MySQL 8.0 부터 mysqldump의 디폴트 옵션은 통계 정보를 가져오도록 변경되었습니다.
이는 MySQL 8.0 information_schema에만 존재하는 테이블이기에
8.0 Utility를 통해 mysqldump를 사용하여 5.X 하위 버전의 DB로 원격 백업을 수행할 경우에는 통계 테이블을 스킵하도록 아래 옵션을 추가해 주시면 됩니다.
- 관련 에러 : Unknown table 'COLUMN_STATISTICS' in information_schema (1109)
- 커맨드 수행 옵션 : mysqldump --column-statistics=0Conclusion
간단하게 적으려고 했는데.. 쓰다보니 장문의 포스팅이 되어 버린것 같습니다.
개인적으로 생각하기에, MySQL 8.0은 운영 측면, 특히나 온라인 DDL 측면에서 굉장히 환영하는 바입니다만.. 새로운 버전이 나왔다고 무조건 적용 하다가는, 기존 서비스에 큰 문제를 일으킬 소지가 많이 있습니다.
사실 위의 언급된 내용 외에도 MySQL 8.0은 우리가 예상하지 못한 버그와 다양한 이슈 사항들로 여전히 분주하게 대응하고 있습니다.
그래서, MySQL 8.0을 도입하기에 앞서서 사전에 체크 해봐야할 사항들을 개인적인 경험을 기반으로 공유를 해보았는데요. 아래와 같이 정리해볼 수 있겠네요.
- Connector/j 버전 체크
- 롤백을 대비한 5.7 호환 콜레이션 지정
- optimizer_switch 핸들링
- 예약어 이슈
- 그 외 체크 사항
- Query Cache 제거
- JDBC Connector 버전의 DB 접근 이슈
- 테이블 대/소문자 구분(lower_case_table_names) 운영중 변경 불가
- expire_logs_days 파라메터 변경
- 0900_ai_ci collation의 이슈
- mysqldump 디폴트 옵션 변경 사항
그러나 늘상 Oracle 사에서는 매 신규 버전이 나올때 마다 압도적인(??) 성능 개선을 보여주는 버전 간 성능 BMT 그래프를 대중들에게 공개해 주시기에… 어르신 or 개발자분들의 문의를 언제까지 피할 수는 없을..ㅠㅠ
어찌보면 DBA 입장에서 서비스와 데이터의 안정성은 가장 중요하게 지켜져야 할 포인트지만 최소한 자신이 관리하는 서비스에 MySQL 8.0 도입 여부가 적합한지에 대해서는 담당 DBA만의 객관적이고 명확한 판단 기준이 필요한 시기가 온 듯 합니다. (어느덧 8.0 Release도 20번대까지 넘어 왔습니다^^;)
기본적인 Grant 문조차 변해버린 MySQL 8.0을 document로만 보며 따라가기가 이제는 조금 버거워 보이며..
다양한 테스트들을 기반으로 실제 서비스에서 직접 운영 경험을 쌓으며 이슈들을 해결해 나가는 게 큰 도움이 될 것 같습니다.
올해에는 MySQL 8.0 뿐 아니라 MySQL과 관련된 다양한 경험들을 공유하길 바라며 이만 마치도록 하겠습니다.
감사합니다^^