Overview
별별DBA 첫 이야기로, 이전에 간단하게 다루었던 MySQL InnoDB memcached plugin을 다루어보도록 하겠습니다. 이전에 개인 블로그에서 포스팅을 했던 내용이기는 하지만, 데이터의 흐름을 잘 조작해보겠다는 나름의 철학을 담은지라.. 세 가지 글(하단)을 하이브리드로 서술하면서 편안하게 읊어보도록 할께요. 🙂
- 1탄 MySQL InnoDB의 메모리 캐시 서버로 변신! – 설정편 –
- 2탄 MySQL InnoDB의 메모리 캐시 서버로 변신! – 모니터링편 –
- 3탄 MySQL InnoDB의 메모리 캐시 서버로 변신! – 활용편 –
Cache layer?
예측할 수 없는 수준의 트래픽은, DB 위주의 데이터 서비스를 단번에 바꾸었다고 생각을 합니다. 물론, 대부분의 중소형 데이터는 적당히(?) DB를 하나 두고 서비스를 어느정도 제공할 수 있겠지만, 기가 단위 트래픽이 유입되는 케이스에서는 변경되지 않는 정적인 데이터를 매번 DB에서 조회하기에는 아무래도 성능적인 한계가 있습니다.

무엇보다! DB는 정해진 제한된 리소스가 있다는 측면에서, 넘치는 트래픽을 모두 DB기반으로만 처리할 수 없는 것은 자명합니다. 그래서 과거 Disk I/O가 좋지 않은 통돌이 디스크 시절, 이런 처리를 메모리 기반으로 서비스하기 위해 알티베이스와 같은 메모리DB로 빈번히 조회되는 데이터를 처리했던 기억이 있네요.(물론, 저는 안했지만. ㅋㅋ)
캐시 레이어의 목적은 여러가지가 있겠지만, 저 개인적으로 두 가지 정도를 나누어보고 싶은데요.
- 캐시에서 큐잉 혹은 선처리 후 비동기로 파일에 기록
- 조회 빈도는 높으나, 변경이 적은 데이터를 메모리에 적재 후 서비스
여기서 이야기할 내용은 바로 후자, 변경은 거~의 없지만, 조회빈도는 굉장히 높은, 추가로 한가지 옵션을 더한다면, 트랜잭션 처리가 되어 완료된 데이터만 보여주고 싶은 요구사항에 참으로 흥미돋을만한 이야기라고 할 수 있겠습니다. (캐시 데이터인데, READ-COMMITTED로 해볼 수 있다!!)
MySQL memcached plugin
다양한 캐시 저장소가 있지만, MySQL memcached plugin에 관심이 간 이유는 단순합니다. 바로, 쿼리 파싱 및 옵티마이저 단계 없이, 바로 InnoDB 데이터에 접근할 수 있다는 것이죠. 과거, MariaDB에 HandlerSocket과 비슷한 컨셉이라는 측면에서 관심이 갈수밖에 없었습니다.

출처: https://dev.mysql.com/doc/refman/8.0/en/innodb-memcached-intro.html
아 물론, memcached 쪽에 정책을 다르게 해서.. 별도의 캐시 메모리를 할당해서 사용해볼 수 있겠지만, SSD와 같이 랜덤I/O가 기대 이상으로 뛰어난 디바이스가 있는 환경에서, 그리고 InnoDB 버퍼풀 메모리가 별도로 존재하는 입장에서 매력이 크게 와닿지는 않았습니다. (물론, InnoDB는 B-Tree이기 때문에, O(1)로 보통 데이터를 룩업하는 해시 구조체와 성능 자체를 비교할 수는 없겠죠.)
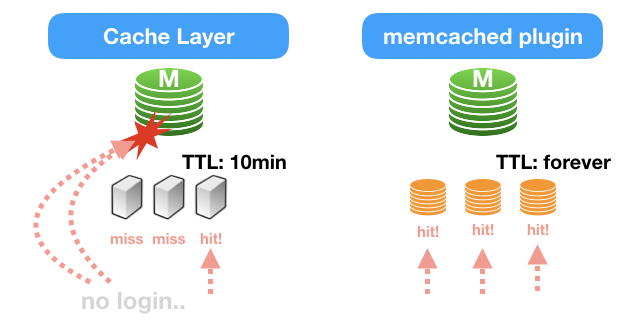
InnoDB데이터에 직접 접근한다? 이 이야기는 곧 파일 기반의 캐싱 레이어라고도 다르게 해석해볼 수 있겠습니다. 즉, expire time이 별도로 존재하지 않는 TTL이 무한대인 캐싱 레이어!! 새로운 가능성을 볼 수 있었습니다.
파일기반의 캐싱레이어? 성능이 걱정될 수밖에 없습니다. 아무리 좋은 기대치를 보일지라도, 엄청난 READ량이 발생하는 캐싱 시스템에서, 응답시간 혹은 안정성이 떨어지면 좋은 솔루션이라고 볼 수 없습니다. 그래서 간단하게 PK기반의 단일 조회 쿼리와 memcached 프로토콜을 통한 InnoDB데이터 룩업 속도를 비교해보았는데요.
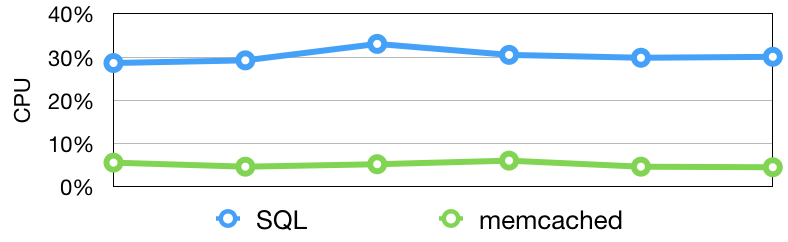
심지어 안정성을 책정해보기 위해서, 대략 10일 정도 초당 7만건 정도의 트래픽을 지속적으로 주면서 스트레스 테스트를 줘봤습니다. 그 결과, 에러는 단 한번도 발생하지 않았고, 초당 0.3ms~0.5ms 정도의 예쁜(?) 응답속도를 보였습니다. 이정도면, 프로덕션에서 캐시로 활용하기에 전혀 손색이 없는 수준이죠. 🙂
+-----+----------+
| ms | seconds |
+-----+----------+
| 0.2 | 99 |
| 0.3 | 661736 |
| 0.4 | 162582 |
| 0.5 | 5686 |
| 0.6 | 1769 |
| 0.7 | 1004 |
| 0.8 | 576 |
| 0.9 | 310 |
| 1.0 | 159 |
| 1.1 | 77 |
| 1.2 | 29 |
| 1.3 | 12 |
| 1.4 | 4 |
| 1.5 | 1 |
+-----+----------+심지어, 14만 GET 오퍼레이션 스트레스를 주기도 했었는데.. 전혀 서비스에 문제가 없었을 뿐만 아니라, 평균 CPU 리소스 사용률은 대략 15% 정도로.. 안정적인 상태를 보였습니다. ㅎㅎ
Monitoring
아무리 서비스가 멋져도, 이 서비스의 건강상태를 실시간으로 체크할 도구가 없다면 꽝이겠죠? 그래서 어떤 방법이든, 가장 효율적인 모니터링 방안을 찾아봐야 하겠는데요. 저는 개인적으로는 prometheus를 활용한 metric수집을 선호합니다.
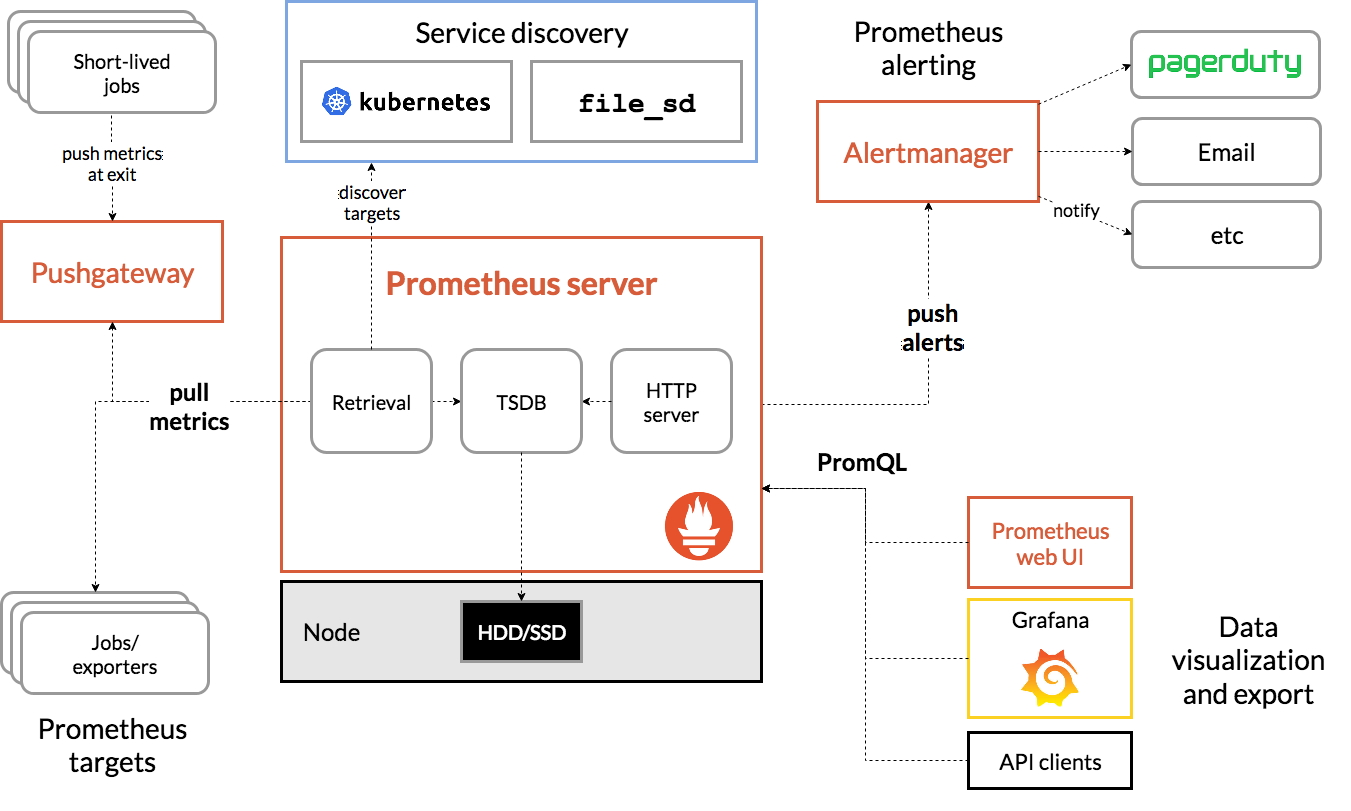
prometheus를 선호하는 이유는 단순합니다. 이미 만들어져 있는 exporter가 굉장히 많다는 것, 만약 원하는 것들이 있다면 나의 구미에 맞게 기능을 추가해서 쉽게 접근할 수 있다는 것! Time-series 기반의 데이터 저장소인 Prometheus로 정말로 효율적으로 모니터링 매트릭 정보를 수집할 수 있다는 것! Prometheus는 로그 수집에 최적화 되어 있다고 과언이 아닙니다.
물론, 현재 Prometheus에서 오피셜하게 내놓은 memcached exporter경우, InnoDB memcached 정보를 수집하기에는 약간의 문제가 있습니다. stats settings 결과 중 4글자 이상의 데이터를 비정상 패턴으로 인지하여, memcached 가 정상적으로 구동중이지 않은 것으로 수집이 되는데, 오픈소스의 묘미는 아무래도 안되는 영역이 있으면 알아서 고쳐서 쓸 수 있다는 점입니다.
// AS-IS ======================
stats := map[string]string{}
for err == nil && !bytes.Equal(line, resultEnd) {
s := bytes.Split(line, []byte(" "))
if len(s) != 3 || !bytes.HasPrefix(s[0], resultStatPrefix) {
return fmt.Errorf("memcache: unexpected stats line format %q", line)
}
stats[string(s[1])] = string(bytes.TrimSpace(s[2]))
line, err = rw.ReadSlice('\n')
if err != nil {
return err
}
}
// TO-BE ======================
stats := map[string]string{}
for err == nil && !bytes.Equal(line, resultEnd) {
s := bytes.Split(line, []byte(" "))
if len(s) == 3 {
stats[string(s[1])] = string(bytes.TrimSpace(s[2]))
} else if len(s) == 4 {
stats[string(s[1])] = string(bytes.TrimSpace(s[2])) + "-" + string(bytes.TrimSpace(s[2]))
} else {
return fmt.Errorf("memcache: unexpected stats line format %q", line)
}
line, err = rw.ReadSlice('\n')
if err != nil {
return err
}
}간단하게 몇줄 수정을 해봄으로써, 이런 정상적이지 않는 처리를 쉽게 해결하였습니다. 이제부터는 prometheus를 통한 매트릭 수집 및 Alert 전송 그리고 Grafana를 통한 실시간 지표 확인! 강력한 모니터링 도구를 얻었습니다.
Beyond physical memory
위에서 나열한 내용정도만으로, 캐시 레이어로 프로덕션에 활용하기에 전혀 손색이 없습니다. 그러나, 이것 이상의 가능성을 상상해보았습니다.
다들 아시겠지만, MySQL의 강력한 기능중에 하나는 바로 데이터 복제, 즉 리플리케이션이라고 생각합니다. 리플리케이션을 통해 안정적으로 마스터 데이터를 복제를 하고, 이를 서비스에 잘 활용한다면, 바로 아래와 같이 READ 분산을 자연스럽게 유도해볼 수 있겠죠. ^^
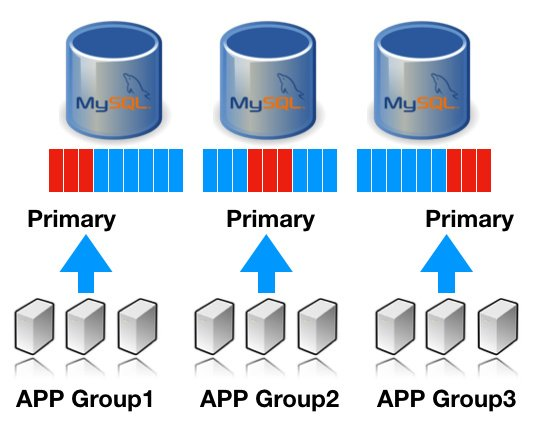
모든 노드는 동일한 데이터를 가지기에, 어느 장비에서 해당 데이터를 읽어도 동일한 결과를 얻습니다. 즉, 평소에는 위 그림처럼 각각 그룹별로 캐시 데이터를 서비스하고 있다가, 특정 노드 장애시에는 근처에 위치한 다른 MySQL 쪽에서 데이터를 끌어와도 서비스적으로 전혀 문제가 없다는 이야기죠.
게다가, 각각의 어플리케이션에서 필요한 만큼의 데이터를 분산해서 읽기 때문에, 복제되어 있는 모든 데이터가 InnoDB 버퍼풀에 포함되어야할 이유가 없습니다. 즉, 사라지지 않는 파일 기반의 캐시 데이터가 자연스럽게 분산되어 서비스되는 것이죠.
한가지 더! MySQL의 복제를 잘 활용한다면 빠뜨릴 수 없는 것이 바로 바이너리로그입니다. 바이너리 로그는 MySQL에서 데이터가 변경된 내역을 저장하는 파일로, 이 데이터를 슬레이브에서 그대로 리플레이(마스터에서 변경된 이력을 그대로 적용)하여 복제하는 역할을 가집니다.
이중 ROW포멧 경우에는 변경된 데이터 내용 자체를 포함하게 되는데, FULL이미지 경우, 변경 전/후 모든 데이터를 포함하고 있기에, 아래와 같이 재미난 캐싱용 CDC구조를 생각해볼 수 있습니다.
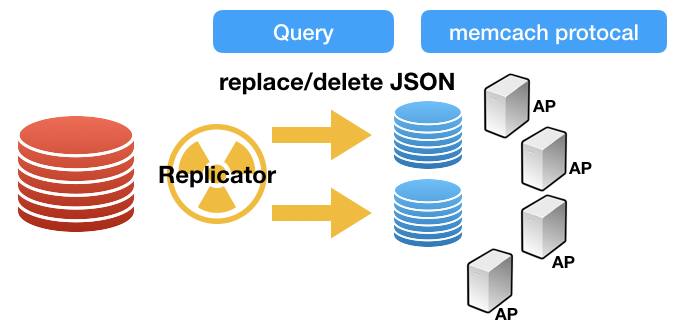
데이터 변경이 발생하는 MySQL 마스터 디비에서 캐싱 연관된 테이블(이를테면, 회원정보) 데이터 변경이 발생하면, 이를 감지하여 JSON 형태로 변환해서 캐시 MySQL에 데이터를 넣어주는 역할을 하는 리플리케이터를 한번 만들어보는 것이죠.
이렇게되면, 왼쪽 서비스(붉은색) 디비에는 그 어떤 조작도 없이, 마치 데이터가 흐르는 물처럼 자연스럽게 JSON으로 변환되어 비휘발성의 캐싱 레이어로 저장이 됩니다. 그러면, 어플리케이션에서는 JSON으로 변환된 데이터를 기반으로 비동기 캐싱 서비스를 수행하면 됩니다. 물론, 여기서는 쉽게 이야기를 해봤지만, 복제 지연과 같은 많은 사이드이펙트에 대응하는 방어 로직이 많이 필요하기는 하겠죠. ㅎㅎ
Conclusion
세 개의 시리즈를 하나의 블로그로 부드럽게 이어가기는 참으로 고달픈 일이네요. 사실, 이전 블로그 세 개를 쭉 읽어보는 것이 더욱 이해가 빠를 수 있습니다. 지금까지 제가 이야기한 내용이 각자의 서비스에서 최적의 솔루션이라고 절대 생각하고 있지 않습니다.
다만, InnoDB memcached plugin같은 대안이 우리가 현재 처한 문제 상황에서는 꽤나 적합한 해결방안을 제시할 수 있었던 것이고, 이것을 MySQL 고유의 좋은 기능과 같이 하모니를 이루어보면서 새로운 가능성을 생각해볼 수 있었던 과정을 이야기해보고 싶었습니다.
장애가 없는 시스템이 목적이 아닌, 장애 가능성이 낮은 견고한 시스템을 만드는 것, 설혹 장애가 나더라도 빠르게 정상화가 되는 시스템!! 그러기 위해서는 각 시스템들의 좋은 기능들을 잘 조합해서 활용하고 상상해본 나름의 솔루션, 이런 것들을 이런 자리를 빌어 재밌게 한번 풀어보고 싶었습니다. 🙂 (아. 지루했으려나요…..ㅜㅜ)
이제 다음 포스팀부터는, 저 뿐만 아닌 다양한 분야에서 멋지게 데이터를 다루고 있는 별별 다른 DBA들의 이야기도 들어보는 자리를 마련해보겠습니다. 벌써 기대가 되네요. 긴 글 읽어주셔서 감사합니다. ^^